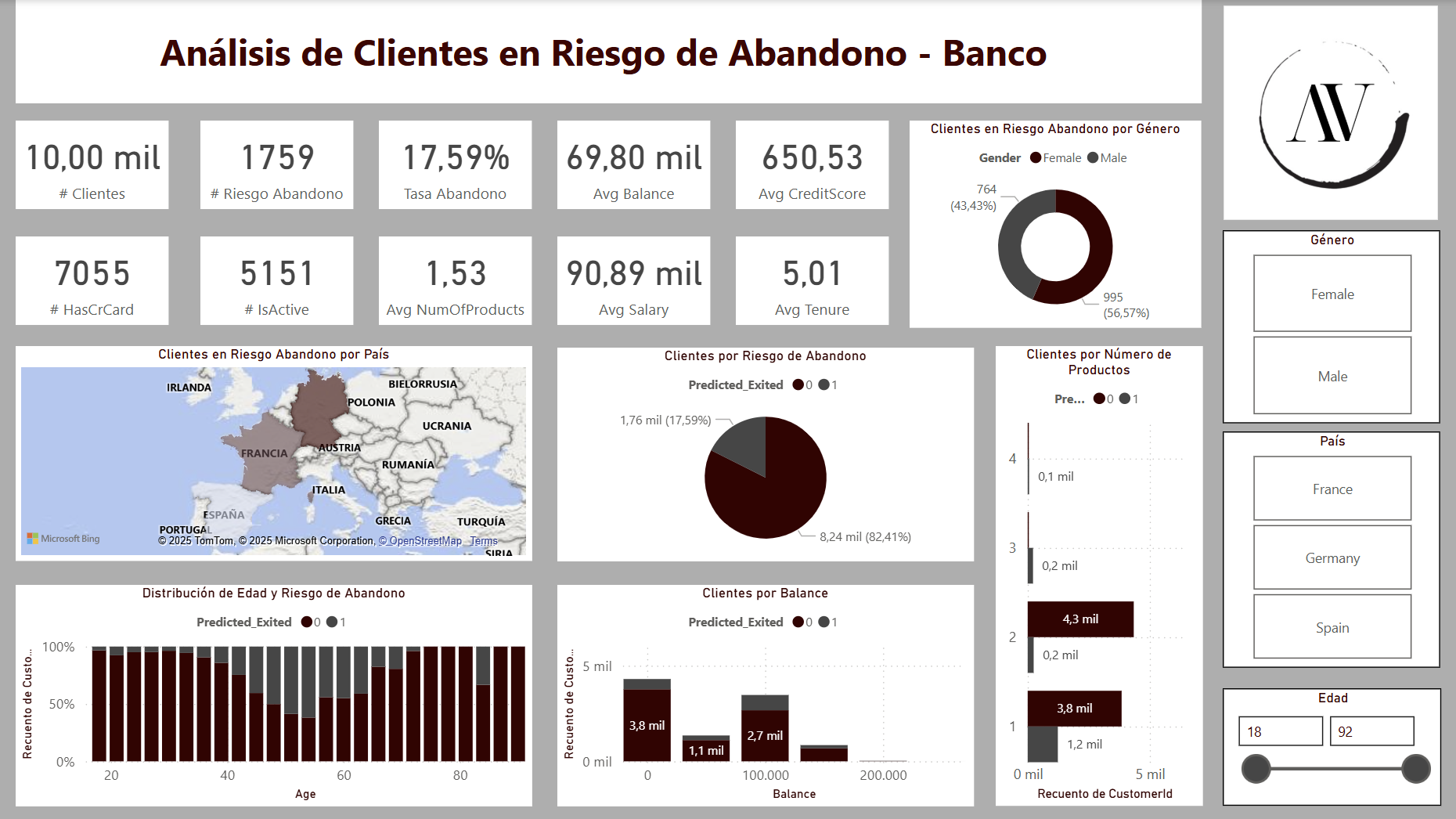
Este proyecto desarrolla una solución basada en machine learning para predecir el abandono de clientes (churn) en una entidad bancaria, proporcionando a la compañía una herramienta clave para la toma de decisiones estratégicas basadas en datos.
El análisis comienza con la evaluación de diferentes modelos supervisados en R (regresión logística, árbol de decisión y random forest), seleccionando la alternativa más precisa para identificar clientes en riesgo de abandono. Los resultados se integran en Power BI para facilitar su visualización y monitorización por parte de los equipos directivos.
Además, el uso de técnicas de interpretabilidad avanzada en Python mediante valores SHAP permite comprender el peso de cada variable en la predicción individual, aportando información valiosa para diseñar campañas de retención personalizadas y estrategias de marketing segmentado. Este enfoque integral mejora la capacidad de la organización para anticipar comportamientos críticos de sus clientes y optimizar sus acciones de fidelización.
Se comparan distintos modelos de aprendizaje supervisado utilizadondo R.
Se probaron tres modelos: Regresión Logística, Árbol de Decisión y Random Forest, evaluando su precisión y capacidad predictiva.
El modelo elegido finalmente fue Random Forest, que ofreció mejores resultados.
El resultado de este modelo se exportó a un CSV (predicciones_rf.csv) para su análisis posterior en Power BI.
library(readr)
churn <- read_csv("churn.csv")
View(churn)
datos <- churn
# Análisis descriptivo de los datos
summary(datos)
str(datos)
# Cuántos y qué % de clientes se van del banco
table(datos$Exited)
prop.table(table(datos$Exited))
# Categóricas
datos$Gender <- as.factor(datos$Gender)
datos$Geography <- as.factor(datos$Geography)
datos$Exited <- as.factor(datos$Exited)
# Split 80/20
library("caTools")
division <- sample.split(datos$Exited, SplitRatio = 0.8)
entrenamiento <- subset(datos, division==TRUE)
test <- subset(datos, division==FALSE)
prop.table(table(datos$Exited))
prop.table(table(entrenamiento$Exited))
prop.table(table(test$Exited))
# Regresión Logística
reg_logistica <- glm(Exited ~ Age + Gender + Geography + CreditScore + Balance + NumOfProducts + IsActiveMember,
data = entrenamiento, family = "binomial")
summary(reg_logistica)
prediccionmodelo <- predict(reg_logistica, newdata = test, type = "response")
prediccionmodelocod <- ifelse(prediccionmodelo > 0.5, 1, 0)
library(caret)
confusionMatrix(as.factor(prediccionmodelocod), as.factor(test$Exited))
# Árbol de decisión
library(rpart)
library(rpart.plot)
modelo_arbol <- rpart(Exited ~ Age + Gender + Geography + CreditScore + Balance + NumOfProducts + IsActiveMember,
data = entrenamiento, method = "class")
summary(modelo_arbol)
rpart.plot(modelo_arbol)
prediccionarbol <- predict(modelo_arbol, newdata = test, type = "class")
confusionMatrix(as.factor(test$Exited), as.factor(prediccionarbol))
# Random Forest
library(randomForest)
set.seed(123)
modelo_rf <- randomForest(Exited ~ Age + Gender + Geography + CreditScore + Balance + NumOfProducts + IsActiveMember,
data = entrenamiento, ntree = 500, mtry = 3, importance = TRUE)
print(modelo_rf)
prediccion_rf <- predict(modelo_rf, newdata = test)
confusionMatrix(as.factor(prediccion_rf), as.factor(test$Exited))
varImpPlot(modelo_rf)
# Exportar resultados para Power BI
datos$Predicted_Exited <- predict(modelo_rf, newdata = datos)
write.csv(datos, "predicciones_rf.csv", row.names = FALSE)
En este bloque se muestra el código principal en Python utilizado para entrenar el modelo de Random Forest, analizar la importancia de las variables y aplicar técnicas de interpretabilidad mediante SHAP values. Este análisis permite comprender tanto el funcionamiento interno del modelo como el impacto de cada variable en la predicción individual de cada cliente.
# Instalación de librerías (en Google Colab)
!pip install shap
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
import shap
# Cargar los datos
data = pd.read_csv("churn.csv")
train, test = train_test_split(data, test_size=0.3, random_state=0, stratify=data['Exited'])
# Eliminación de columnas innecesarias
train = train.drop(['RowNumber', 'Surname', 'CustomerId'], axis=1)
test = test.drop(['RowNumber', 'Surname', 'CustomerId'], axis=1)
# Conversión de variables categóricas
train_processed = pd.get_dummies(train)
test_processed = pd.get_dummies(test)
# Rellenar valores nulos
train_processed = train_processed.fillna(train_processed.mean(numeric_only=True))
test_processed = test_processed.fillna(test_processed.mean(numeric_only=True))
test_processed = test_processed[train_processed.columns]
# Crear matrices de entrenamiento y test
X_train = train_processed.drop(['Exited'], axis=1)
Y_train = train_processed['Exited']
X_test = test_processed.drop(['Exited'], axis=1)
Y_test = test_processed['Exited']
# Entrenar modelo Random Forest
random_forest = RandomForestClassifier(n_estimators=100)
random_forest.fit(X_train, Y_train)
random_forest_preds = random_forest.predict(X_test)
print('The accuracy of the Random Forests model is :', metrics.accuracy_score(random_forest_preds, Y_test))
# Interpretabilidad con SHAP
explainer = shap.TreeExplainer(random_forest)
# Ejemplo de predicción e interpretación
choosen_instance = X_test.loc[2739]
shap_values = explainer.shap_values(choosen_instance)
shap.initjs()
shap.force_plot(explainer.expected_value[1], shap_values[1], choosen_instance)




